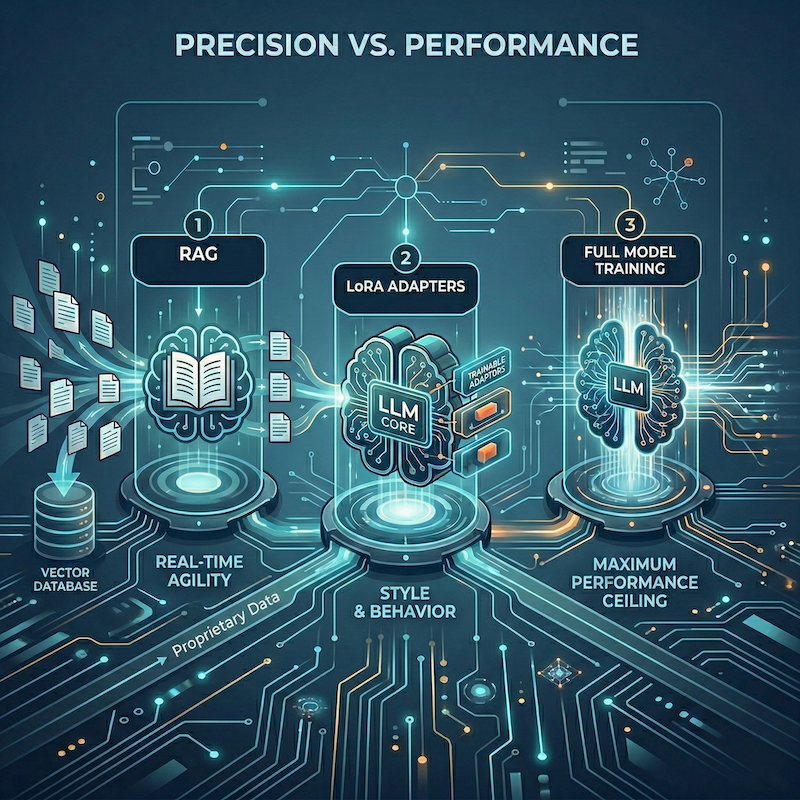
Precision vs. Performance: Choosing Between RAG, LoRA, and Full Model Training
By: Chris Gaskins and Dominick Romano
In the current landscape of enterprise AI, the question is no longer whether to adopt Large Language Models (LLMs), but how to effectively ground them in your proprietary data. As organizations move past the “chatbot wrapper” phase, they face a critical architectural decision: Should you use Retrieval-Augmented Generation (RAG), fine-tune with LoRA adapters, or invest in full model training?
At Drainpipe, we believe that efficiency is the ultimate metric for AI success. Choosing the wrong path doesn’t just waste budget — it creates hallucination debt and brittle systems that can’t adapt at the speed of your business.
Here is how to navigate the three pillars of AI optimization — and more importantly, how to know which one is right for you.
1. Retrieval-Augmented Generation (RAG): The “Open Book” Approach
RAG is currently the dominant standard for enterprise AI deployment. Rather than embedding knowledge directly into a model’s weights, RAG equips the model with a dynamic “library card.” When a query arrives, the system searches a vector database for relevant documents and injects them into the prompt as real-time context.
Think of it less like teaching a model and more like giving a brilliant analyst access to the right filing cabinet at exactly the right moment.
The Strengths
- Real-Time Data Agility: If your documentation changes at 9:00 AM, your RAG system can reflect those changes by 9:01 AM — zero retraining required.
- Built-In Verifiability: RAG systems can cite their sources. This “grounding” capability is non-negotiable for legal, medical, and technical compliance use cases.
- Low Barrier to Entry: No expensive GPU clusters needed for training. A solid data pipeline and a well-architected vector database are your primary investments.
The Trade-offs
RAG is bounded by the model’s context window. When the information needed to answer a question is scattered across dozens of documents, synthesis quality degrades. Equally important: RAG doesn’t learn your company’s unique voice, jargon, or formatting conventions — it simply reads what is placed in front of it. For style and behavioral consistency, you’ll need to look elsewhere.
2. LoRA Adapters: The “Specialist” Approach
LoRA (Low-Rank Adaptation) is a form of Parameter-Efficient Fine-Tuning (PEFT). Rather than updating every parameter in a multi-billion-weight model, LoRA inserts a small, trainable adapter layer on top of the frozen base model. The result is a lightweight, swappable module that meaningfully shifts model behavior — without the cost of full retraining.
If RAG gives a model facts, LoRA gives it a personality.
The Strengths
- Behavioral and Stylistic Control: LoRA is the premier tool for teaching a model to adhere to a specific output format (structured JSON, internal report templates), a proprietary coding style, or a defined communication tone.
- Deep Domain Mastery: When your industry operates in a specialized “dialect” — whether that’s clinical oncology, derivatives trading, or aerospace engineering — LoRA helps the model internalize those nuances at a structural level.
- Modular, Scalable Architecture: Maintain a single base model and deploy department-specific adapters as needed. A 100MB LoRA adapter for Legal. Another for Engineering. Another for Sales. One infrastructure, infinite specialization.
The Trade-offs
LoRA carries an inherent knowledge cutoff problem. Once an adapter is trained, it is static. It has no awareness of events, updates, or decisions made after its training window closed — unless you retrain it. For rapidly evolving domains, this is a meaningful constraint.
3. Full Model Training: The “Foundational” Approach
Full model training means updating every weight in a model — or building one from scratch — on a massive, domain-specific dataset. This is the highest-investment, highest-ceiling option available.
The Strengths
- Maximum Performance Ceiling: Full training is the only path to true state-of-the-art (SOTA) results on highly niche tasks that general-purpose models like Llama or GPT have never meaningfully encountered.
- Architectural Sovereignty: You own the weights, the embedded logic, and the safety filters — entirely. No dependency on third-party model providers, no licensing ambiguity.
The Trade-offs
For the vast majority of enterprises, full training is overkill — and a costly mistake. Compute bills can reach into the millions. The specialized ML talent required is scarce and expensive. And there is a real risk of catastrophic forgetting, where a model becomes so optimized for a narrow task that it loses the general reasoning capabilities that made it valuable in the first place.
The Comparison Matrix
| Feature | RAG | LoRA Adapters | Full Training |
|---|---|---|---|
| Primary Goal | Fact Retrieval | Style / Format / Nuance | Foundational Capability |
| Data Freshness | Real-time | Static (requires retraining) | Static |
| Compute Cost | Low (inference only) | Medium (one-time / periodic) | Extremely High |
| Time to Implement | Weeks | Weeks to Months | Months to Years |
| Accuracy Profile | High (for facts) | High (for behavior) | Maximum (for niche tasks) |
Which Path Should You Take?
Scenario A: The Internal Knowledge Base
Goal: A bot that answers questions about HR policies, compliance documentation, or technical manuals.
Winner: RAG. The data changes too frequently to justify training cycles, and the ability to cite the exact source document — down to the page — is often a hard requirement.
Scenario B: The Proprietary Code Assistant
Goal: An AI that writes code using your company’s internal, proprietary framework or enforces a specific architectural pattern.
Winner: LoRA. The model needs to internalize a syntax and style it was never exposed to during pre-training. RAG can surface examples, but only LoRA can make the behavior native.
Scenario C: The Industry-Specific Foundation Model
Goal: A biotech firm building a model to interpret private lab results and predict protein interactions.
Winner: Full Training. The underlying data logic is so fundamentally different from general “Internet English” that adaptation is insufficient. The model must be built from the ground up on domain-native data.
The Drainpipe Strategy: The Hybrid Path
In practice, the most sophisticated and resilient enterprise AI systems don’t choose one approach — they orchestrate all three.
Our recommended architecture typically follows this progression:
- Start with RAG to handle your dynamic, high-velocity data needs. This gives you immediate, verifiable accuracy with minimal infrastructure risk.
- Layer in a LoRA adapter once the system is stable, to align the model’s voice, enforce output formatting standards, and embed domain-specific behavioral norms.
- Reserve full training for the rare cases where your data is genuinely unlike anything in the public domain — and where the business case justifies the investment.
This layered approach delivers what neither strategy achieves alone: the accuracy of a librarian combined with the expertise of a seasoned specialist.
Closing Summary
The future of enterprise AI isn’t about deploying the biggest model. It’s about deploying the smartest architecture — one that aligns with your data reality, operational tempo, and business objectives.
Whether you’re building vector pipelines or training custom weights, the goal is the same: transforming raw, proprietary data into reliable, actionable intelligence.
Looking to optimize your AI architecture? Visit www.drainpipe.io to learn how we help enterprises build smarter, more efficient AI systems — at scale.